In the previous article in this series, I wrote about pragmatic AI engineering and how reviewing model-generated code is the new bottleneck. We focused on tiered intelligence and token mirrors to manage developer cognitive load. But as I spent my evenings applying these ideas to build out my personal project portfolio, I ran into a deeper surprise.
When I started building AI applications this year, I thought the hardest part would be getting the models to produce good answers.
I was wrong.
Over the last few months, I spent my evenings toggling between four separate codebase directories in my editor: plotsense/ (a title verification system for property documents), intraday-lab/ (a research platform for market backtesting), hungergames/ (a team lunch preference calculator), and cartsense/ (a credit card rewards optimizer).
Each codebase lived in its own folder. Each had different data inputs, different schemas, and entirely different domains. But as I switched between these workspaces, I was hit by a strange feeling of repetition.
I wasn't repeating prompts, model choices, or vector indices. In fact, once I had a basic frontier model prompt or ocr extraction loop working, I rarely edited them. They just worked.
The AI call was a commodity finished in an hour. The next three weeks were spent building a custom application around it.
That was the moment my mental model shifted. I've stopped thinking of AI as the decision maker. It is just another source of evidence. My real job has become engineering the system that decides what evidence to trust.
Defining the Evidence Layer
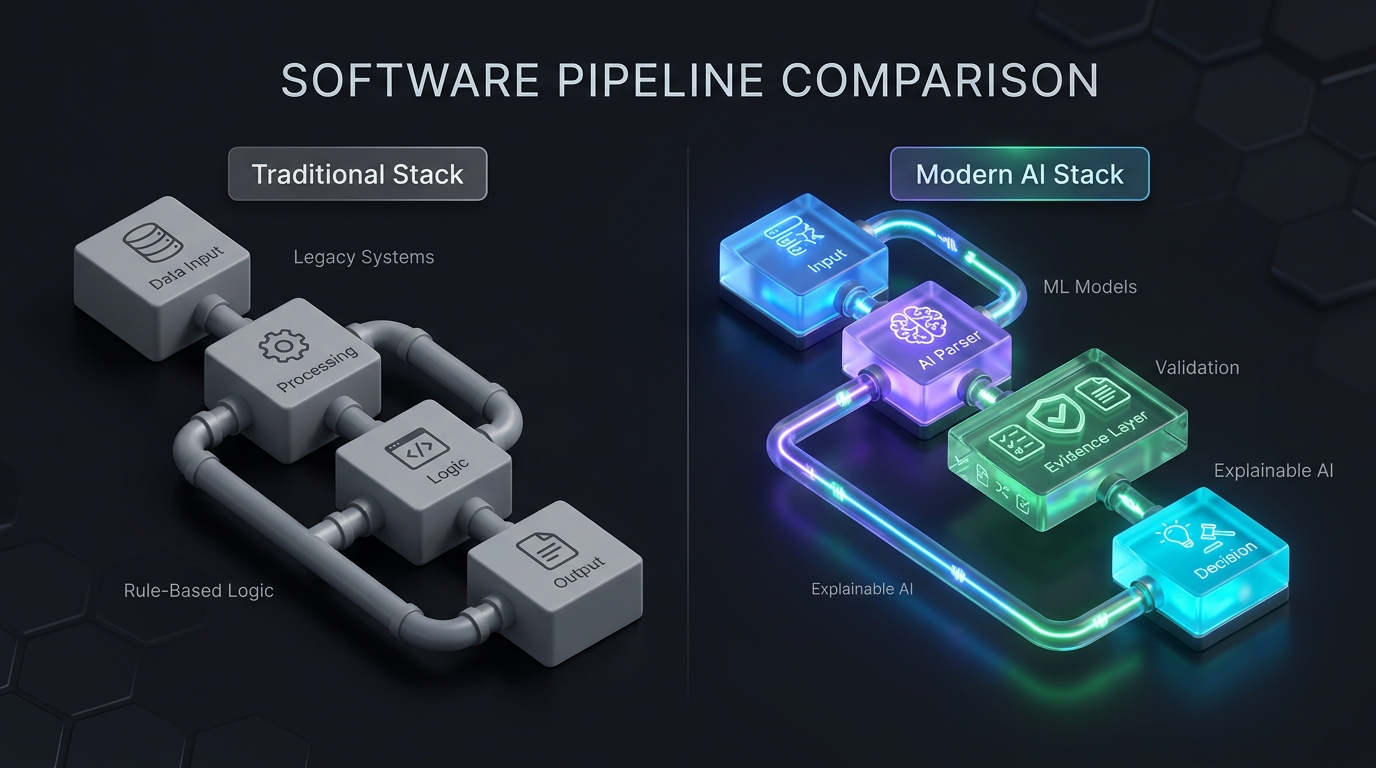
For decades, traditional software architecture followed a predictable path: raw data was processed by deterministic business logic and handed to a user interface.
AI changes this flow. It introduces a probabilistic component into the core stack. To make these systems safe and useful, we have to insert an entirely new architectural layer: The Evidence Layer. Its only job is to convert probabilistic outputs into deterministic decisions.
⚡ Interactive Stack Blueprint
Hover or click nodes to trace how raw data matures into decisions.
Validates schema formats, checks boundaries, and verifies document survey numbers match prior historical deeds.
if (extracted.survey !== expected.survey) {
throw new TitleDefectError("Survey drift detected");
}
The Primary Proof: Property Chain Verification
To see why this layer is necessary, take the property title verification system in plotsense/.
Using OCR can extract text from an Encumbrance Certificate, and an LLM can summarize the transactions. But neither tells you whether it's actually safe to buy the land. The AI output—no matter how accurate—is merely evidence.
The real engineering work is the validation code that sits above the model's output to verify the chain of custody. It must answer questions that the model cannot:
- Can I trust the data? Does this specific document belong to the same property boundary, or has the survey number mutated?
- Can I verify the result? Is there a missing transaction link in the 30-year ownership history?
- Can I explain the reasoning? If the system warns of a title defect, can it pinpoint the exact year and deed where the continuity broke?
- Can I maintain this system? Will this validation hold up when bank formats drift or model versions update?
Extracting the names and dates is a commodity task handled by the model. Resolving the chain of custody is a deterministic software problem.
The Pattern Repeats
The division between probabilistic evidence and deterministic decisions repeated across every project I built:
| Domain | AI gives me (Evidence) | The Evidence Layer (The Real Work) |
|---|---|---|
| Property (PlotSense) | Structured document entities | Title chain continuity validation |
| Finance (CartSense) | Raw merchant name & amount | Reward optimization & refund match rules |
| Restaurant (Lunch Hub) | Dish reviews & classifications | Team diet compatibility matching |
| Markets (Strategy Lab) | Stock news & technical indicators | Expectancy simulator & risk safety rails |
In the rewards optimizer, the AI can classify a transaction from a receipt. That is evidence. The application must still run the deterministic rules to map that merchant to your credit card rewards matrices and verify if it matches a refund within a 7-day window.
In the market lab, the AI can summarize stock sentiment. That is evidence. The application must still run the backtest simulations, calculate expectancy, and enforce the hardcoded risk safeguards that limit order sizes.
In every case, the AI did not make the decision. It merely provided structured, high-signal evidence to a system designed to verify it.
The Shift in AI Engineering
This realization has changed how I measure my work.
A year ago, I measured progress by how good my prompts were. Today, I measure progress by how much confidence my system gives the person making the decision.
I suspect that's the direction AI engineering is heading.